Map
Map
- 无法对 map 的 key 或 value 取址
- map 的 key 必须为 可比较类型,以支持对 key 相等的判断
- 删除 map 不存在的键值对时,不会报错,相当于没有任何作用
- 读取 map 不存在的键值对时,读取到的值为类型零值
- 往一个 nil map 添加值会引发 panic,对 nil map 的读取和删除等同于对正常 map 读取删除不存在的键值对
语法
// 声明&初始化
// 只是声明一个map,没有初始化,m1=nil,此时赋值引发panic
var m1 map[type]type
// 初始化为空map
m1 := map[type]type{}
// 同上,初始化为空map
m1 := make(map[int]string, 0)
//操作
// 赋值,自动为map分配空间,但此时map需已初始化,不能为nil
m1[a] = b
// 取值,键值不存在时 ok=false
value, ok = m1[a]
// 删除指定 key
delete(m1, a)
map 并非并发安全,并发读写 map 会导致 panic 且该 panic 无法被 recover 捕获
结构
map 为引用类型,用 make 函数创建初始化 map 时会在堆上分配一个 runtime.hmap 类型的数据结构,并返回指向这块内存区域的指针
type hmap struct {
count int // 元素的个数
B uint8 // bucket数量的对数
flags uint8 // 标志位,包括用于判断并发写的写标志位
noverflow uint16 // 溢出桶的大概数量
hash0 uint32 // hash种子,为哈希函数的结果引入随机性
buckets unsafe.Pointer // 2^B个桶对应的指针数组,指向bmap
oldbuckets unsafe.Pointer // 扩容时记录旧buckets数组的指针
nevacuate uintptr // 疏散进度计数器(小于此的桶已被疏散)
extra *mapextra // 用于保存溢出桶的地址
}
type mapextra struct {
overflow *[]*bmap // buckets的溢出桶
oldoverflow *[]*bmap // oldbuckets的溢出桶
nextOverflow *bmap // 保存一个指向空闲溢出桶的指针
}
// 静态bmap
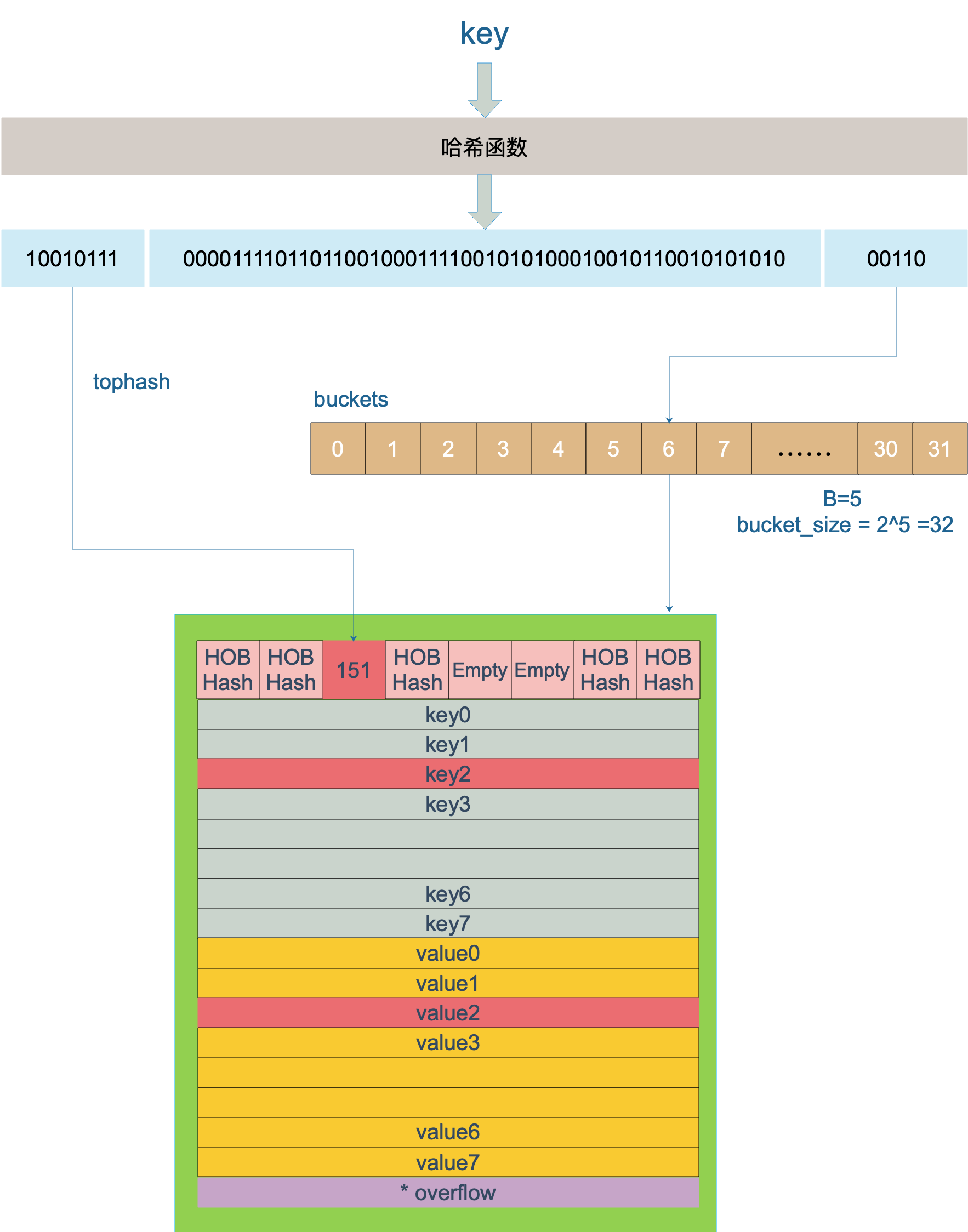
type bmap struct {
tophash [bucketCnt]uint8
}
// 在编译期间动态产生的新结构体
type bmap struct {
topbits [8]uint8 // 存储哈希值的高8位
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr // 溢出bucket的地址
}
// flag 可能值
iterator = 1 // 可能有迭代器使用 buckets
oldIterator = 2 // 可能有迭代器使用 oldbuckets
hashWriting = 4 // 有协程正在向 map 中写入 key
sameSizeGrow = 8 // 等量扩容
map 中单个哈希桶 bmap 最多存储8个元素,溢出后新建溢出桶存储,使用 overflow 指向溢出桶位置
当 map 的 key 和 value 都不是指针且都小于 128 bytes 的情况下,GC 把 bmap 标记为不含指针不进行扫描,这时会把 bmap 的 overflow 移动到 hmap 的 extra 字段中
map 使用特殊的 tophash 标注元素状态,在存储 tophash 时会对 key 计算出来的哈希值增加值 minTopHash
emptyRest = 0 // 空 cell,且后续 cell 都为空
emptyOne = 1 // 空 cell
evacuatedX = 2 // key,value 已经搬迁完毕,key搬迁至第一个新桶中
evacuatedY = 3 // 同上,但key搬迁至第二个新桶中
evacuatedEmpty = 4 // 空的 cell,同时 cell 已经被迁移到新的 bucket
minTopHash = 5 // tophash 的最小正常值
操作实现
创建
创建 map 底层调用 makemap 函数,返回 hmap 结构的指针,而 makeslice 返回 slice 结构体本身
当 map 和 slice 作为函数参数时,在函数参数内部对 map 的操作会影响 map 自身;而对 slice 却不会
查找
- key 经过哈希计算后得到 hash 值,共 64 个 bit 位
- 根据最后 B(bucket 数量的对数)位确定桶编号
- 遍历桶内
tophash数组,对比 hash 值高 8 位查找 key,有匹配则进一步比对 key 本身,相同返回对应 value - 若无匹配且
overflow指针不为空,去溢出桶内继续匹配 - 未找到 key 时会返回一个 value 相应类型的零值
对于读取,编译器分析代码后,根据是否返回 bool 变量的两种语法对应到底层两个不同的函数 mapaccess1 和 mapaccess2
此外根据 key 的不同类型,编译器会将查找、插入、删除的函数用更具体的函数替换,以优化效率
写入
向 map 中插入或修改 key 调用 mapassign 函数
mapassign 函数返回 value 地址,通过该地址进行 value 更新
- 首先进行并发写检测,判断是否有其他协程在进行写操作,是则 panic
- 函数根据传入的键获取 hash 值,进而拿到对应的哈希和桶
- 如果处于扩容状态且当前桶对应旧桶未迁移,先将旧桶进行迁移
- 遍历比较桶中存储的
tophash和键的哈希,在遍历过程中确定桶内首个空闲位置- 如果在桶内找到 key,更新 value
- 如果桶内 key 不存在,将 k-v 放置在之前确定的空闲位
- 如果当前桶已满(没有空闲位),调用
newoverflow创建溢出桶或者使用预先在hmap.noverflow中创建好的溢出桶来保存数据,新创建的桶不仅会被追加到已有桶的末尾,还会增加哈希表的noverflow计数器
- 正式安置 key 之前,检查 map 是否需要扩容,如需要则进行扩容后重新进行查找插入(key 的分布发生了变化)
- 更新 map 相关值,如果是插入则元素数量
count++,清零并发写标志位
删除
底层函数为 mapdelete
- 进行并发写检查
- 计算 hash 找到对应桶,如此时 map 正在扩容,触发一次搬迁
- 删除对应 key
- 更新 map 相关值,元素数量
count--,清零并发写标志位
Go 语言中的 map 结构在删除键值对时,并不会真正的删除,而是将其标记为已删除
因为 Go 语言中的 map 结构是通过哈希表实现的,当删除键值对时,如果真正的删除该键值对,那么可能会导致哈希表中的其他键值对的位置发生变化,这样就需要重新计算哈希值,这样会影响性能
如果找到了目标 key,则把当前桶该槽位对应的 key 和 value 伪删除,将该槽位的 tophash 置为 emptyOne
如果发现当前槽位后面没有元素,则将 tophash 设置为 emptyReset,并循环向前检查元素并将同样处于 emptyOne 状态的元素置为 emptyReset,直到遇到非空元素
目的是将 emptyReset 状态尽可能地向前面的槽推进,增加查找效率,在查找的时候发现了 emptyReset 状态就停止查找
遍历
遍历 map 时先调用 mapiterinit 函数初始化迭代器,然后循环调用 mapiternext 函数进行 map 迭代
- 首先随机确定一个开始遍历的起始桶和桶内槽位,开始遍历当前桶和当前桶的溢出桶
- 根据遍历初始化的时候选定的随机槽位开始遍历桶内的各个 key/value
- 遍历到处于扩容状态的 bucket
newb时,首先会找到newb对应的旧桶oldb,遍历旧桶中将要分配至newb的一部分 key,跳过其他 key(将在遍历到其他 key 对应桶时被遍历)
- 遍历到处于扩容状态的 bucket
- 继续遍历 bucket 溢出指针指向的溢出链表中的溢出桶
- 假如重新遍历到了起始桶 startBucket 的 offset,则说明遍历完了,结束遍历
Map 每次遍历输出元素的顺序不一致
通过使 for range 遍历 Map 的索引起点随机,go 强制要求程序不依赖 map 的顺序,原因在于:
- Hash 表中数据每次插入的位置是变化的,同一个 map 变量内,数据删除再添加的位置也有可能变化,因为在同一个桶及溢出链表中数据的位置不分先后
- Go 的扩容不是一个原子操作,是渐进式的,所以在遍历 map 的时候,可能发生扩容,一旦发生扩容,key 的位置就发生了重大的变化,下次遍历 map 的时候结果就不可能按原来的顺序
扩容
步骤:
- 将当前桶数组由
buckets指针转移到oldbuckets指针 - 创建新桶数组,挂载到
buckets指针 - 每次对 map 进行写操作时触发从 oldbucket 中迁移一个桶的数据到 bucket
- 在扩容没有完全迁移完成之前,每次查找数据时先遍历 oldbuckets 再遍历 buckets
因为 Go 语言哈希的扩容不是一个原子过程,所以两种扩容都需要判断当前 map 是否已经处于扩容状态,避免二次扩容造成混乱
等量扩容
创建等量新桶,桶内元素重排,填满前置空位,删除空的溢出桶
触发时机:溢出桶数量太多
- B < 15 时溢出桶数量超过 2^B
- B > 15 时溢出桶数量超过 2^15
等量扩容不会使桶内元素顺序变化
潜在问题:
如果插入 map 的 key 桶哈希都一样,就会落到同一个 bucket 里,超过 8 个就会产生 overflow bucket,结果也会造成 overflow bucket 数过多,此时移动元素解决不了问题,因为这时整个哈希表已经退化成了一个链表,操作效率变成了 O(n)
成倍扩容
创建两倍数量新桶,B++,元素可能发生桶迁移(最后 B 位确定的桶编号发生变化)
触发时机: map 写操作时装载因子(元素数量/bucket 数量) > 6.5
成倍扩容会使桶内元素顺序变化
特殊情况:
使用 math.NaN() 作为 key 时,每次对其计算 hash 得到的结果都不一样
math.NaN() 的含义是 not a number,类型是 float64,这个 key 永远不会被查找到,只有在遍历整个 map 的时候出现,所以可以向一个 map 插入任意数量的 math.NaN() 作为 key。
当搬迁碰到 math.NaN() 的 key 时,只通过 tophash 的最低位决定分配到两个新桶中的哪一个