Go 并发模型
Go 并发模型
协程 Goroutine
协程是用户空间内与内核空间的系统线程相绑定的线程
协程与线程间的关系通过协程调度器控制
一个 goroutine 栈在其生命周期开始时占用空间很小(一般2KB),并且栈大小可以按需增大和缩小,goroutine 的栈大小限制为1GB,但是一般不会用到这么大
通过 go func() 创建协程
Goroutine 父子协程之间不存在依赖关系,主协程例外,主协程退出时其他协程自动退出
同级协程之间的执行顺序随机
协程 VS 线程
线程由CPU调度,是抢占式的
线程可以理解为一个进程的执行实体,它是比进程力度更小的执行单元,也是真正运行在cpu上的执行单元,线程是操作系统调度资源的基本单位
一般OS线程栈大小为2MB
协程占用了更小的内存空间,也降低了上下文切换的开销
协程由用户态调度,通常情况下是协作式的,一个协程让出CPU后,才执行下一个协程(Go存在抢占式协程)
- 内存占用
- 创建一个 goroutine 的栈内存消耗为 2 KB,实际运行过程中,如果栈空间不够用,会自动进行扩容
- 创建一个 thread 则需要在创建时指定堆栈大小,通常消耗 1 MB 栈内存,而且还需要一个被称为 “a guard page” 的区域用于和其他 thread 的栈空间进行隔离
- 创建销毁开销
- Thread 创建和销毀都会有巨大的消耗,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池
- 而 goroutine 因为是由 Go runtime 负责管理的,创建和销毁的消耗非常小,是用户级
- 切换开销
- 当 threads 切换时,需要保存各种寄存器,以便将来恢复,一般而言,线程切换会消耗 1000-1500 ns
- Goroutine 切换只需保存三个寄存器:Program Counter, Stack Pointer 和 BP,切换时间约为 200 ns
协程缺点
- 协程频繁地进行栈扩展操作,也会消耗内存,导致内存占用较多
- 协程默认在一个线程上运行,也就是协程无法直接利用多个 CPU 核心进行计算,所以在高负载或者需要高并行处理的场景下,使用协程不能充分发挥多核处理器的性能优势
- 省流:go 适用于被阻塞的,且需要大量并发的场景,而不适用于大量计算的多线程,遇到此种情况,更好使用线程去解决
- 协程只能在 go 语言运行环境使用,其他语言用不了,会有一些限制
调度结构
Go 调度器也叫 Go 运行时调度器,或 Goroutine 调度器,指的是由运行时在用户态提供的多个函数组成的一种机制,目的是为了高效地调度 G 到 M 上去执行
核心思想:
- 复用线程
- 利用多核并行能力,限制同时运行的线程数等于 CPU 核心数
- 任务及时执行
- 线程私有运行任务队列
- 任务窃取机制,线程空闲时可偷取其他线程任务
- 交接机制,线程阻塞时将队列传给其他线程
- 抢占机制,保证公平性,防止协程饥饿
- V1.14 引入基于信号的真抢占机制,解决了 GC 时无法被抢占的问题
Runtime 会在程序启动的时候,创建 M 个线程(CPU 执行调度的单位),之后创建的 N 个 goroutine 都会依附在这 M 个线程上执行,这就是 M:N 模型
核心结构体sched
M(thread) G(goroutine) P(Processor)
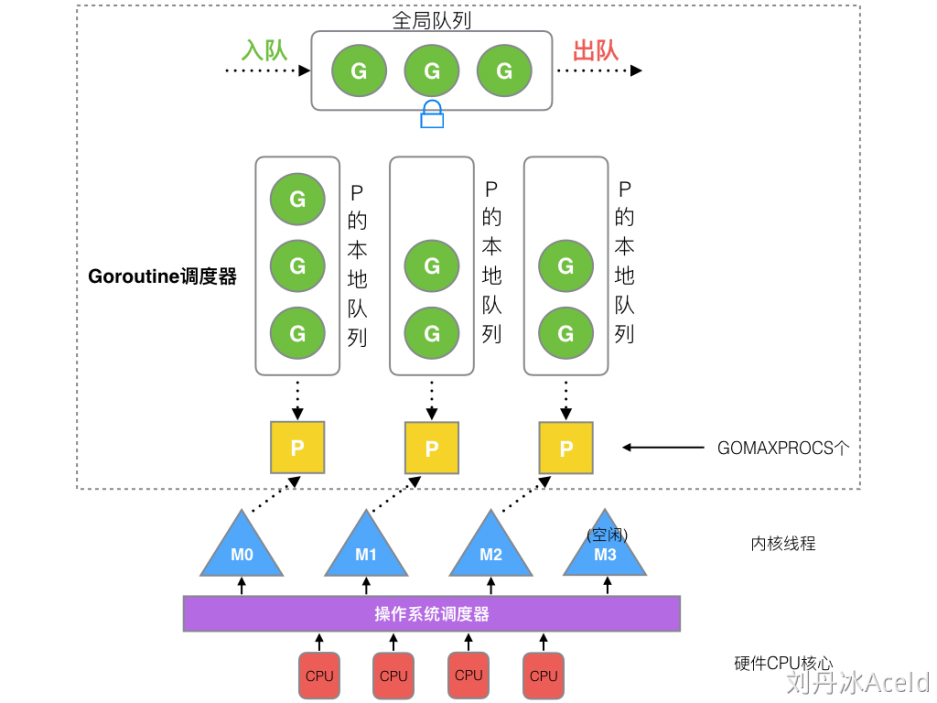
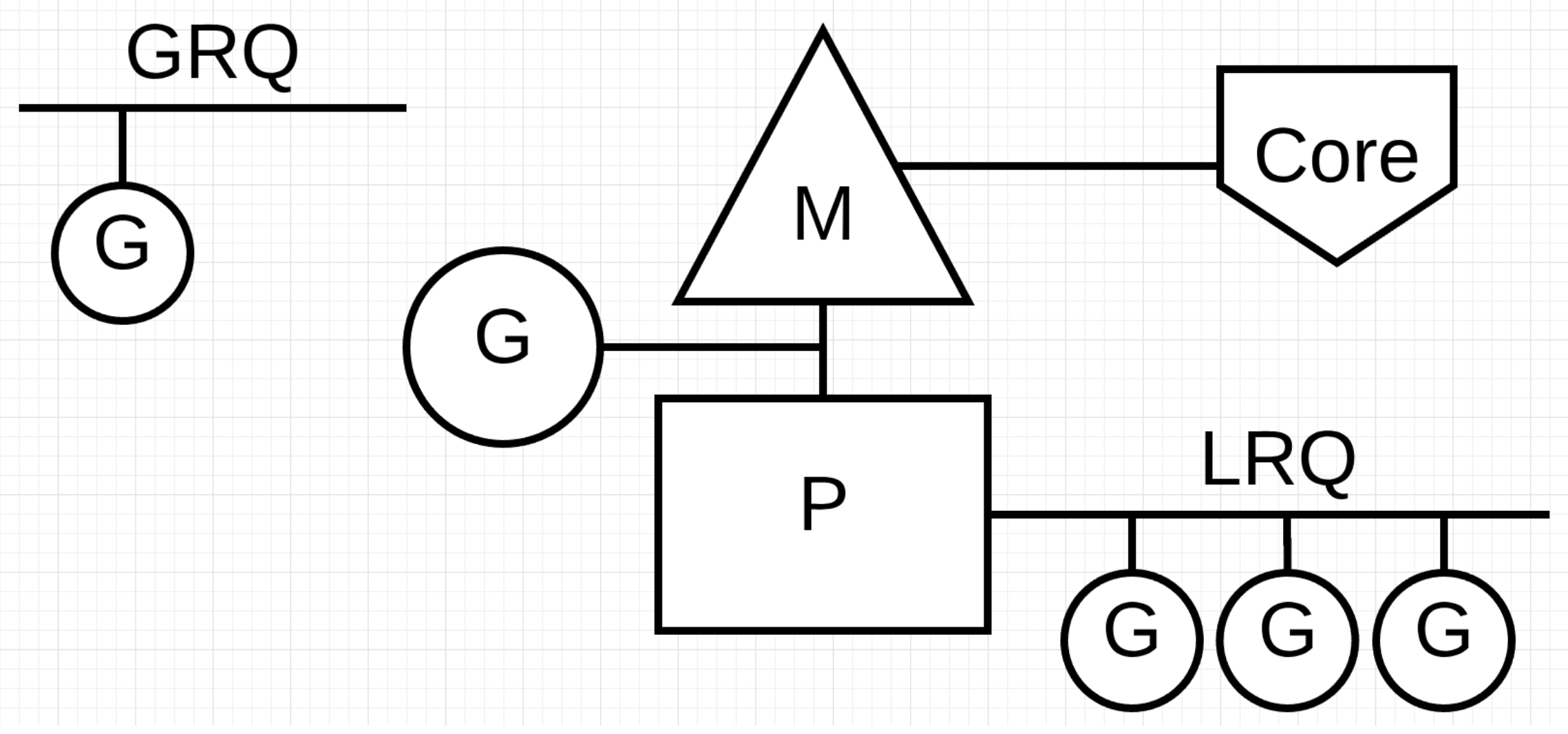
全局队列:存放等待运行的 G,需加锁访问
P 的本地队列:同样存放等待运行的 G,数量最大为256个,通过 CAS 的方式无锁访问
G
Goroutine 是 Go 语言调度器中待执行的任务,在 Go 语言运行时使用私有结构体 runtime.g 表示
type g struct {
stack stack // 当前 Goroutine 使用的栈
stackguard0 uintptr // 用于调度器抢占式调度
preempt bool // 抢占信号
preemptStop bool // 抢占时将状态修改成 `_Gpreempted`
preemptShrink bool // 在同步安全点收缩栈
_panic *_panic // 最内侧的 panic 结构体
_defer *_defer // 最内侧的延迟函数结构体
m *m // 当前 Goroutine 占用的线程,可能为空
sched gobuf // 存储 Goroutine 的调度相关的数据
atomicstatus uint32 // Goroutine 的状态
goid int64 // Goroutine 的 ID
waitsince int64 // g 被阻塞之后的近似时间
waitreason string // g 被阻塞的原因
...
}
// 描述栈的数据结构,栈的范围:[lo, hi)
type stack struct {
lo uintptr // 栈顶,低地址
hi uintptr // 栈低,高地址
}
stackguard0字段被设置成 StackPreempt 意味着当前 Goroutine 发出了抢占请求
goid 对开发者不可见,Go 团队认为引入 ID 会让部分 Goroutine 变得更特殊,从而限制语言的并发能力
sched 字段的 `runbbimg.jiangsk.topo
type gobuf struct {
sp uintptr // 栈指针
pc uintptr // 程序计数器
g guintptr // 持有该gobuf的goroutine
ret sys.Uintreg // 系统调用的返回值
...
}
`gobuf` 中的内容会在调度器保存或者恢复上下文的时候用到,其中的栈指针和程序计数器会用来存储或者恢复寄存器中的值,改变程序即将执行的代码
#### 数量
Go 对 Goroutine 的数量没有限制,但 Goroutine 的实际数量受到系统资源的限制
可以使用 协程池 来控制协程的并发数量
#### 状态
Goroutine 总共有以下 9 种状态以及其他一些 GC 相关和未使用状态
| 状态 | 描述 |
|:-------------:| ------------------------------------------------------------------------------------------- |
| `_Gidle ` | 刚刚被分配并且还没有被初始化 |
| `_Grunnable` | 没有执行代码,没有栈的所有权,存储在运行队列中 |
| `_Grunning` | 可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P |
| `_Gsyscall` | 正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上 |
| `_Gwaiting` | 由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上 |
| `_Gdead` | 没有被使用,没有执行代码,可能有分配的栈 |
| `_Gcopystack` | 栈正在被拷贝,没有执行代码,不在运行队列上 |
| `_Gpreempted` | 由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒 |
| `_Gscan` | GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 |
可以将状态简单分类为三种:等待中、可运行、运行中
> 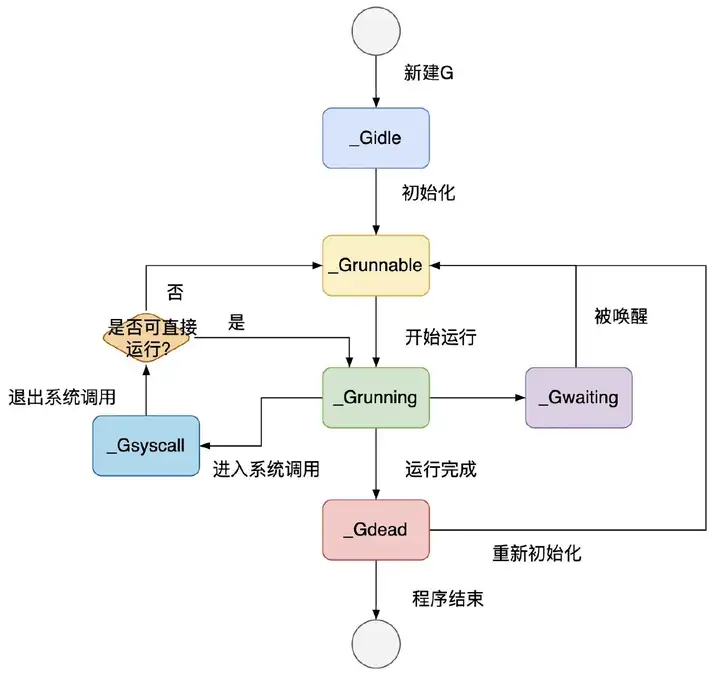
> 上图省略了一些垃圾回收的状态
对于执行结束的 dead G 并不会释放,而是缓存在 P 本地或全局,以待复用
### M
M 是操作系统线程,使用私有结构体 `runtime.m` 表示
```go
type m struct {
g0 *g // 持有调度栈的特殊Goroutine
gsignal *g // 处理signal的g
mstartfn func() // M的起始函数(go语句所携带的函数)
curg *g // 在当前线程上运行的用户Goroutine
p puintptr // 执行go代码时持有的处理器P
nextp puintptr // 暂存的与当前M有潜在关联的处理器P
oldp puintptr // 执行系统调用之前绑定的处理器P
spinning bool // 表示当前M是否处于自旋状态
lockedg guintptr // 表示与当前M锁定的G
...
}
g0 是一个runtime中比较特殊的 goroutine,它会深度参与运行时的调度过程,包括 Goroutine 的创建、大内存分配和 CGO 函数的执行
M0 是启动程序后的编号为0的主线程,对应的实例在全局变量 runtime.M0 中,不需要在 heap 上分配,M0负责执行初始化操作和启动第一个 G,之后 M0和其他的 M 一样受 P 控制
g0是每次启动一个 M 时首先创建的 goroutine,仅用于负责调度队列中的 G
g0不指向任何可执行的函数。每个 M 都会有一个自己的 g0,在调度或系统调用时会使用 g0的栈空间
全局变量的 g0 是 M0 的 g0
数量
调度器最多可以创建 10000 个线程 M,由 runtime.debug 中的 SetMaxThreads 函数设置,但实际上受系统限制通常无法达到
其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行
大多数情况下都使用 Go 的默认设置,线程数约等于 CPU 数,默认的设置不会频繁触发操作系统的线程调度和上下文切换,所有的调度都会发生在用户态,由 Go 语言调度器触发,能够减少很多额外开销
状态
M 只有两种状态
- 自旋状态,表示 M 绑定了 P 又没有获取 G
- 非自旋状态,表示正在执行 Go 代码中,或正在进入系统调用,或空闲
自旋状态下 M 努力获取任务至任务列表并执行,找不到的时候会进入非自旋状态,之后会休眠,直到有工作需要处理时,被其他工作线程唤醒,又进入自旋状态
P
处理器 P 是线程和 Goroutine 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列
通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率
P 维护一个局部可运行的 G 队列,可以通过 CAS 的方式无锁访问
type p struct {
id int32 // 在 allp 中的索引
status uint32 // one of pidle/prunning/...
schedtick uint32 // 每次调用 schedule 时会加一
syscalltick uint32 // 每次系统调用时加一
m muintptr // 反向存储的线程
// 处理器持有的本地队列. 不加锁访问
runqhead uint32
runqtail uint32
runq [256]guintptr // 使用数组实现的循环队列
runnext guintptr // 线程下一个需要执行的 G
// 空闲的 G 队列,G 状态 status 为 _Gdead,可重新初始化使用
gFree struct {
gList
n int32
}
...
}
数量
因为调度器在启动时就会创建 GOMAXPROCS 个处理器,所以处理器 P 的数量一定会等于 GOMAXPROCS,这些处理器会绑定到不同的内核线程上,GOMAXPROCS 通常等同于系统 CPU 核数,以最大程度地利用 CPU
M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以即使 P 的默认数量是1,也有可能会创建很多个 M 出来
状态
| 状态 | 描述 |
|---|---|
_Pidle |
处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空 |
_Prunning |
被线程 M 持有,并且正在执行用户代码或者调度器 |
_Psyscall |
没有执行用户代码,当前线程陷入系统调用 |
_Pgcstop |
被线程 M 持有,当前处理器由于垃圾回收被停止 |
_Pdead |
当前处理器已经不被使用 |
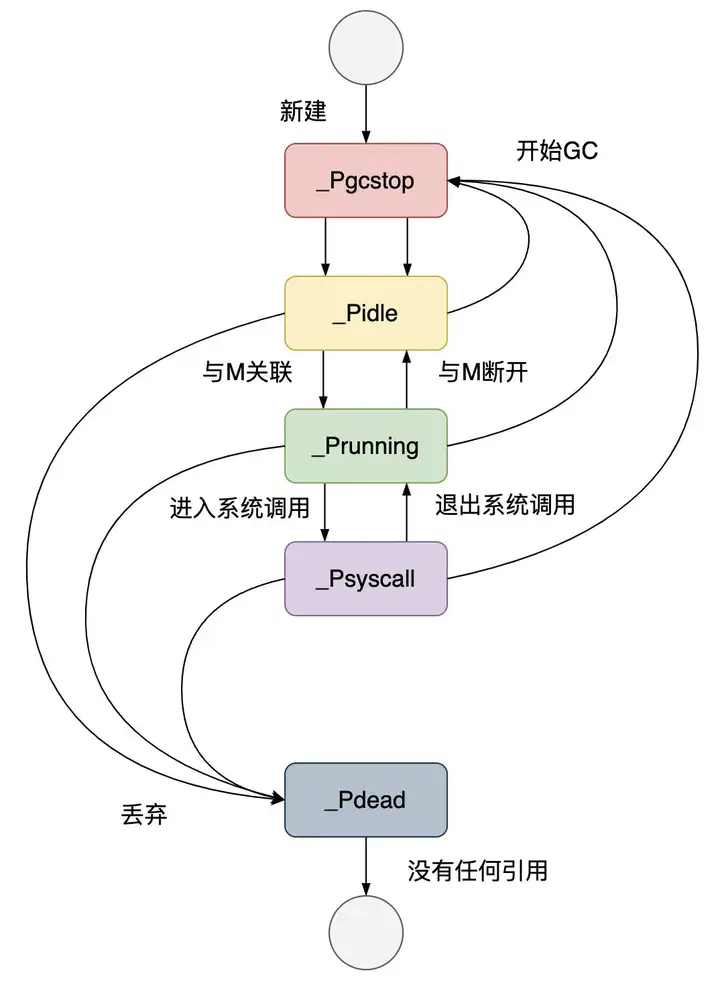
调度器
在程序运行过程中,仅有一份 schedt 调度器结构体,其维护了调度器的所有信息
// schedt 存储了调度器的状态和信息
type schedt struct {
goidgen atomic.Uint64 // 用于生成唯一的 goroutine ID
// lastpoll 和 pollUntil 用于记录最近的网络轮询时间和下一次网络轮询的时间
lastpoll atomic.Int64 // 最近一次网络轮询的时间,如果当前正在轮询,则为0
pollUntil atomic.Int64 // 当前轮询将要睡眠的时间
lock mutex // 用于保护整个结构体状态和信息的一致性
midle muintptr // 等待工作的 idle m
nmidle int32 // 等待工作的 idle m 数量
nmidlelocked int32 // 等待工作的被锁住的 idle m 的数量
mnext int64 // 已创建的 m 的编号和下一个可用的 M ID
maxmcount int32 // 允许的最大 m 数量(或 die)
nmsys int32 // 不计入死锁检测的系统 m 数量
nmfreed int64 // 累计已释放的 m 的数量
ngsys atomic.Int32 // 记录系统创建的 Goroutine 数量
pidle puintptr // 等待工作的 idle p
npidle atomic.Int32 // idle p 的数量
// nmspinning 记录了spin-g(处于 Gwaiting 状态且等待着被唤醒的 goroutine) 的 p 数量,
nmspinning atomic.Int32
// needspinning 记录了是否有 goroutine 进入 spin 状态。这些状态的变更需要使用 lock 锁进行同步。
needspinning atomic.Uint32
runq gQueue // 全局 goroutine 队列
runqsize int32 // 全局 goroutine 队列的元素数量
// disable 控制对调度器的禁用
// 使用 schedEnableUser 来控制。
// disable 由 sched.lock 保护
disable struct {
// user 用于禁用用户 Goroutine 的调度
user bool
runnable gQueue // 暂存可运行的 G
n int32 // runnable 的长度
}
// gFree 是存储 dead G 的全局缓存
gFree struct {
// lock 用于保护 gFree 状态的一致性
lock mutex
stack gList // 具有 stack 的 G
noStack gList // 没有 stack 的 G
n int32
}
// sudog 引用的中央缓存
sudoglock mutex
sudogcache *sudog
// defer 指针的中央池
deferlock mutex
deferpool *_defer
// freem 是一个等待被释放的 m 的列表,当 m.exited 被设置时才会被释放。它链接到 m.freelink 上。
freem *m
gcwaiting atomic.Bool // GC 是否在等待运行
// stopwait、stopnote、sysmonwait 和 sysmonnote 用于协助 GC 的运行
stopwait int32 // 停止所有 goroutine 的等待时间
stopnote note // 停止所有 goroutine 的通知
sysmonwait atomic.Bool
sysmonnote note
// 如果 p.runSafePointFn 被设置了,那么 safepointFn 应该在每个 P 的下一次 GC safepoint 调用 safepointFn。
// safepointWait 和 safepointNote 用于辅助 safepoint 的运行。
safePointFn func(*p) // P 运行 safepointFn 函数
safePointWait int32 // P 并行 evict arena (追踪内存快照) 时停止的等待时间
safePointNote note
profilehz int32 // CPU profiling 时钟频率
// procresizetime 和 totaltime 用于记录调整 GOMAXPROCS 的时间和总运行时间
procresizetime int64 // 最后一次更改 GOMAXPROCS 的访问时间
totaltime int64 // ∫gomaxprocs dt up to procresizetime,即 gomaxprocs 的积分
sysmonlock mutex // 用于保护 sysmon 如 GC 的运行
// timeToRun 是调度器的调度延迟
timeToRun timeHistogram // g 状态 _Grunnable 阶段到 _Grunning 阶段的时间分布
// idleTime 记录了 P 的空闲 CPU 时间总和,用于重新计算估计的 GC 阻塞时间。在每个 GC 循环开始时进行清零
idleTime atomic.Int64 // 归零在每个 GC 循环开始之前。
totalMutexWaitTime atomic.Int64 // 用于记录 goroutine 在等待 sync.Mutex{} 互斥锁时所花费的总时间。
}
g0
每个调度器的结构体有两个 G,一个是 crug,代表结构体 M 当前绑定的结构体 G,另一个是 g0,是带有调度栈的特殊的 goroutine
普通的 goroutine 的栈是在堆上分配的可增长的栈,而 g0的栈是 M 对应的线程的栈,所有调度相关的代码,会先切换到该 goroutine 栈中再执行,也就是说线程的栈也是用的 g 实现,而不是使用 os 的
g0所使用的栈就是 Go 程序进程所创建的 M 线程的线程栈,与相关的 task_struck 相关联而未与 M 绑定(不是 running 状态的 goroutine)的 goroutine 的协程栈也是存放在进程的堆空间中的
早期模型
Go 早期为 GM 模型,将传统线程拆分为了 M 和 G ,为了充分利用轻量级的 G 的低内存占用、低切换开销的优点,会在当前一个 M 上绑定多个 G,某个正在运行中的 G 执行完成后,G0 调度器会将该 G 切换走,将其他可以运行的 G 放入 M 上执行,这时一个 G0 程序中只有一个 M 线程
优点在于用户态的 G 可以快速切换,缺点在于无法利用多核加速能力,且当前 G 阻塞会阻塞唯一 M
之后 Go 使用多线程调度器,多个 M 对应多个 G
缺点
- 全局锁、中心化状态带来的锁竞争导致的性能下降
- M 会频繁交接 G,导致额外开销、性能下降,每个 M 都得能执行任意的 runnable 状态的 G
- 每个 M 都需要处理内存缓存,导致大量的内存占用并影响数据局部性
- 系统调用频繁阻塞和解除阻塞正在运行的线程,增加了额外开销
调度机制
调度流程
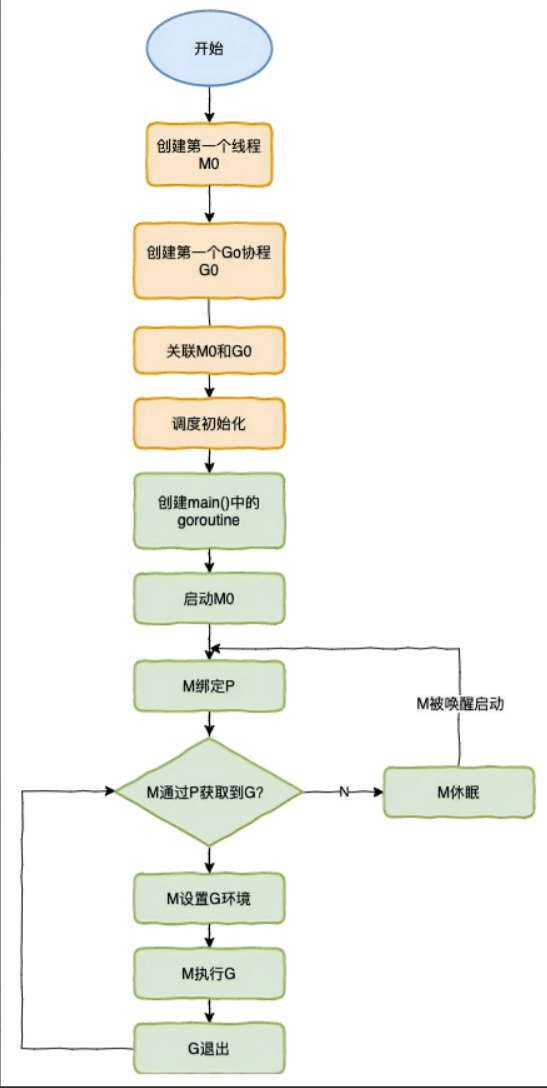
没有 G 可执行的 M 进入自旋状态,以在新 G 创建时能够立刻有 M 可以运行,
调度器启动
部分全局变量
// src/runtime/runtime2.go
allglen uintptr // 所有 g 的长度
allgs []*g // 保存所有的 g
allm *m // 保存所有的 m
allp []*p // 保存所有的 p,个数为gomaxprocs
gomaxprocs int32 // p 的最大值,默认等于 ncpu
ncpu int32 // cpu核数,程序启动时,会调用 osinit 函数获得此值
sched schedt // 调度器结构体对象,记录了调度器的工作状态
// src/runtime/proc.go
m0 m // 代表进程的主线程
g0 g // m0 的 g0,即 m0.g0 = &g0
在程序初始化时,这些全局变量都会被初始化为零值,因此程序刚启动时 allgs,allm 和allp 都不包含任何 g,m 和 p
启动逻辑:
- 初始化 g0 和 m0,并将二者互相绑定, m0 是程序启动后的初始线程,g0 是 m0 线程的系统栈代表的 G 结构体,负责普通 G 在 M 上的调度切换
runtime.schedinit():负责 M、P 和各种运行时组件的初始化过程- 调用
runtime.mcommoninit()初始化 M 的全局队列allm - 调用
runtime.procresize()初始化全局 P 队列allp
- 调用
runtime.newproc():负责获取空闲的 G 或创建新的 Gruntime.mstart():启动调度循环
获取环境变量 GOMAXPROCS 后就会调用 runtime.procresize 更新程序中处理器的数量,这时整个程序不会执行任何用户 Goroutine,调度器也会进入锁定状态,runtime.procresize 的执行过程如下:
- 如果全局变量
allp切片中的处理器数量少于期望数量,会对切片进行扩容 - 使用 new 创建新的处理器结构体并调用
runtime.P.Init初始化刚刚扩容的处理器切片队列 - 通过指针将线程
M0和处理器allp[0]绑定到一起 - 调用
runtime.P.Destroy释放不再使用的处理器结构 - 通过截断改变全局变量 allp 的长度保证与期望处理器数量相等
- 将除
allp[0]之外的处理器 P 全部设置成_Pidle并加入到全局的空闲队列中
调用 runtime.procresize 是调度器启动的最后一步,在这一步过后调度器会完成相应数量处理器的启动,等待用户创建运行新的 Goroutine 并为 Goroutine 调度处理器资源
调度器循环
- 运行函数
schedule() - 从全局队列(
runtime.globrunqget())、 P 本地队列(runtime.runqget())、其他各个地方(runtime.findrunnable) 获取一个可执行的 G - 调用
runtime.execute()执行 G - 调用
runtime.gogo()在汇编代码层面上真正执行 G - 调用
runtime.goexit0()执行 G 的清理工作,重新将 G 加入 P 的空闲队列 - 调用
runtime.schedule()进入下一次调度循环
调度循环中,优先从本地队列获取 G 执行,不过每隔61次,就会从全局队列获取 G 以避免饥饿
创建 G
某一绑定线程 M1的处理器 P1 上的协程 G1 通过 go func() 创建新 G2 后,由于局部性,G2 优先放入 P 的本地队列
当创建 G 时 P1 的本地队列(长度256)已满,P1 本地队列中前半部分的协程(G2~G129)和当前 runnext 所指向的协程(G257)一起放入全局队列,本地队列中剩下的协程(G130~G256)往前移动,runnext 被替换为新协程 G258
创建新的 G 时,运行的 G 会尝试唤醒其他空闲的 M 去绑定 P 以执行任务
如果 G2 唤醒了 M2,M2 成功与 P2绑定后,会先运行 M2 的 G0,这时 M2 没有从 P2 的本地队列中找到 G,会进入自旋状态
自旋状态的 M 会不断尝试从全局空闲线程队列里面获取 G 放到 P 本地队列去执行,系统中最多有 GOMAXPROCS 个自旋的线程,多余的线程进入休眠状态
获取的数量满足公式:n = min(len(globrunqsize)/GOMAXPROCS + 1, len(localrunsize/2)),保证每个 P 至少从全局队列中获取一个 G,同时不获取过多 G 以维持负载均衡
切换 G
G1完成运行后 M1 上运行的 Goroutine 会切换为 G0 以负责调度协程的切换(运行 schedule() 函数),从 M1 上 P1 的本地运行队列获取 G2 去执行
一次协程调度过程跟线程的调度一样,也会发生协程的上下文切换,同样需要保存协程的执行现场,这样才能够切回 g 接着上次继续执行,协程的执行现场主要是三个个寄存器 rsp,rip,rbp 的值:
rsp:指向函数调用的栈顶rip:指向程序要执行的下一条指令地址rbp:存储函数栈帧的起始地址
这些寄存器主要保存在 goroutine 的 sched 字段结构中
G 退出
对于 main goroutine,在执行完用户定义的 main 函数的所有代码后,直接调用 exit(0) 退出整个进程
对于普通 goroutine 需要经历一系列的过程
- 跳转到提前设置好的
goexit函数的第二条指令 - 调用
runtime.goexit1 - 调用
mcall(goexit0),mcall函数会切换到 g0 栈,运行goexit0函数,清理 goroutine 的一些字段,并将其添加到 goroutine 缓存池里 - 进入 schedule 调度循环
调度时机
| 情形 | 说明 |
|---|---|
使用关键字 go |
go 创建一个新的 goroutine,Go scheduler 会考虑调度 |
| GC | 由于进行 GC 的 goroutine 也需要在 M 上运行,因此肯定会发生调度,当然,Go scheduler 还会做很多其他的调度,例如调度不涉及堆访问的 goroutine 来运行 |
| 系统调用 | 当 goroutine 进行系统调用时,会阻塞 M,所以当前 g 和 M 都会被调走,同时一个新的 goroutine 会被调度上来 |
| 内存同步访问 | atomic,mutex,channel 操作等会使 goroutine 阻塞,因此会被调度走。等条件满足后(例如其他 goroutine 解锁了)还会被调度上来继续运行 |
同步协作式调度
主动用户让权
协程可以选择主动让渡自己的执行权,主要通过在代码中主动执行runtime.Gosched()函数实现
- 主动调度会从当前协程g切换到g0并更新协程状态由运行中
_Grunning变为可运行_Grunnable - 然后通过
dropg()取消g与m的绑定关系 - 接着通过
globrunqput()将g放入到全局运行队列中 - 最后调用
schedule()函数开启新一轮的调度循环
主动调度弃权
在每个函数调用的序言 (函数调用的最前方)插入抢占检测指令,当检测到当前 Goroutine 被标记为应该被抢占时,则主动中断执行,让出执行权利
异步抢占式调度
- 被动监控抢占
- 当 G 阻塞在 M 上时(系统调用),系统监控会将 P 从 M 上抢夺并分配给其他的 M 来执行其他的 G
- 当 G 由于原子、互斥量或通道操作调用导致阻塞,调度器将把当前阻塞的 G 切换出去,重新调度本地队列中的其他 G 执行
- 被动 GC 抢占
- 当需要进行垃圾回收时,为了保证不具备主动抢占处理的函数执行时间过长,导致垃圾回收迟迟不得执行而导致的高延迟,强制停止 G 并转为执行垃圾回收
Go 应用程序在启动时会开启一个特殊的后台线程 sysmon 来执行系统监控任务,系统监控运行在一个独立的工作线程 M 上,该线程不用绑定逻辑处理器 P
sysmon 检测到长时间(>10 ms)运行的 goroutine 时将其调度到全局队列,抢占的核心逻辑通过 retake() 函数实现
任务窃取机制
处于自旋状态的 M 如果未从全局队列获取到 G ,为了提高并发执行的效率会随机选择一个非绑定 P ,从它的本地队列偷取一半的 G 到自己的队列中
交接机制
当某个 G 执行时发生了阻塞系统调用或其余阻塞操作将 M 阻塞时,如果当前有其他 G 在 P 的本地队列中等待执行,runtime 会把这个线程 M 与 P 分离,然后复用空闲线程(无则创建一个新线程)来服务于这个 P
网络 IO 不会阻塞 M,Go 提供了网络轮询器(NetPoller)来处理网络请求和 IO 操作的问题,其后台通过 kqueue(MacOS),epoll(Linux)或 iocp(Windows)来实现 IO 多路复用
通过使用 NetPoller 进行网络系统调用,调度器可以防止 Goroutine 在进行这些系统调用时阻塞 M,进而让 M 执行 P 的本地队列中其他的 G 而不需要创建新的 M
执行网络系统调用不需要额外的 M,网络轮询器使用系统线程,它时刻处理一个有效的事件循环,有助于减少操作系统上的调度负载
当 M 结束阻塞时
- 首先尝试获取原先的 P
- 失败则尝试连接一个空闲的 P,之前的阻塞 G 进入到这个 P 的本地队列
- 如果获取不到 P,那么这个 M 进入休眠状态,加入到空闲线程中,与 M 绑定的 G 会被放入全局队列中
若 G 创建了 G' 且执行时进行了非阻塞系统调用,则 M 结束调用后优先尝试获取原 P
当 G 因为休眠、通道堵塞、网络堵塞、垃圾回收导致暂停时,会被动让渡出执行的权利给其他可运行的协程继续执行
调度器通过 gopark() 函数执行被动调度逻辑。gopark() 函数最终调用 park_m() 函数来完成调度逻辑
- 首先会从当前协程 G 切换到 G0,并更新 G 状态由运行中
_Grunning变为等待中_Gwaiting - 然后通过
dropg()取消 g 与 m 的绑定关系 - 接着执行
waitunlockf函数,如果该函数返回false,则协程 G 立即恢复执行,否则等待唤醒 - 最后调用
schedule()函数开启新一轮的调度循环
基于信号的真抢占机制
尽管基于协作的抢占机制能够缓解长时间 GC 导致整个程序无法工作和大多数 Goroutine 饥饿问题,但是还是有部分情况下,Go 调度器有无法被抢占的情况,例如,for 循环或者垃圾回收长时间占用线程
为了解决这些问题, Go1.14 引入了基于信号的抢占式调度机制,能够解决 GC 垃圾回收和栈扫描时存在的问题
- M 注册一个 SIGURG 信号的处理函数
sighandler - Sysmon 线程检测到执行时间过长的 goroutine 或 GC STW 时,会向相应的 M发送
SIGURG信号 - 收到信号后,内核执行
sighandler函数,通过pushCall插入asyncPreempt函数调用 - 回到当前 goroutine 执行
asyncPreempt函数,通过mcall切到 g0 栈执行gopreempt_m - 将当前 goroutine 插入到全局可运行队列,M 则继续寻找其他 goroutine 来运行
- 被抢占的 goroutine 再次调度过来执行时,会继续原来的执行流
检查流程在 sysmon gorotuine/线程里面做,抢占函数是 retake,分两步
- 如果有p单次调度超过10ms(死循环情况),需要发起抢占信号,让这个G去全局队列呆着,做惩罚操作,开启下一轮调度
- 检查一下 P,如果下面条件满足一个,就要调用 handoffp,来保证 P 得以从长时间系统调用中释放
a. 当前 P 的 runq 不为空
b. 没有空闲的 P 和 M
c. 当前 P 处于系统调用的时间超过 10ms
handoffp 是为 P 找一个 M 来进行调度,保证 P 得以从长时间系统调用中释放