Mysql索引
Mysql索引
08 索引:排序的艺术.md (lianglianglee.com)
索引常见面试题 | 小林coding (xiaolincoding.com)
索引特点
索引是提升查询速度的一种数据结构
利用索引的前提是索引里的 key 是有序的
缺点:
- 需要占用空间
- 创建和维护索引产生时间和性能开销
适用场景:
- 字段有唯一性限制
- 字段经常用于
WHERE查询 - 字段经常用于
GROUP BY及ORDER BY
不建议使用情况:
- 一般不用于查询的字段
- 表数据少
- 索引字段存在大量重复数据
- 索引字段经常更新
索引分类
- 按数据结构分类:B+tree 索引、Hash 索引、Full-text 索引
- 按物理存储分类:聚簇索引(主键索引)、二级索引(辅助索引)
- 按字段类型分类:主键索引、唯一索引、普通索引、前缀索引
- 按字段个数分类:单列索引、联合索引
InnoDB采用B+树索引结构
B+树索引
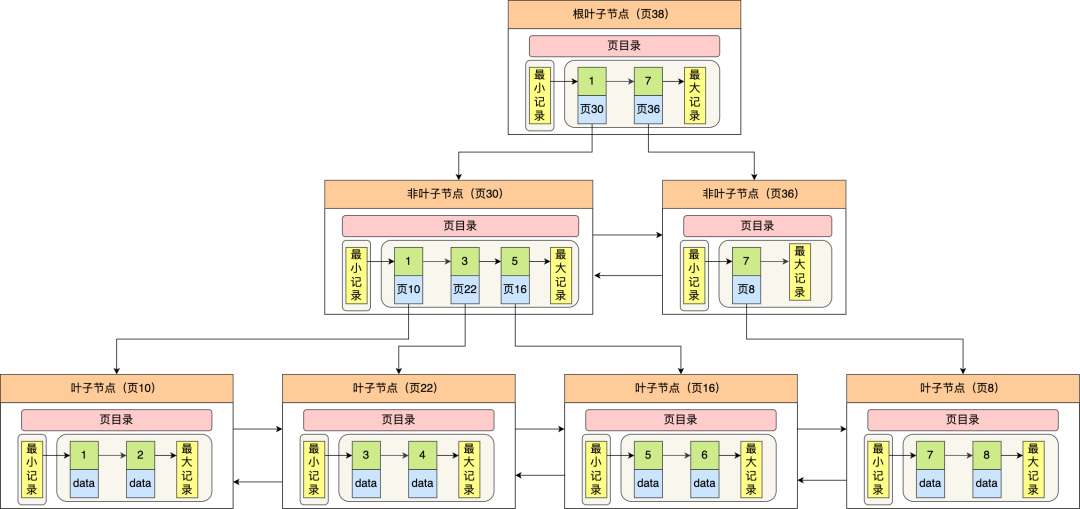
特点:基于磁盘的多叉平衡树,通常只有3~4层,磁盘I/O次数少,查询效率高
B+树是一种多叉树,叶子节点存放实际数据(索引+记录),非叶子节点只存放索引
- 每个节点里的数据按主键顺序存放
- 每一层父节点的索引值都会出现在下层子节点的索引值中,并且是子节点中所有索引的最大或最小
- 每个叶子节点都包含有前后叶子节点的指针,构成双向链表,有助于范围查找
- B+ 树在删除根节点的时候,由于存在冗余的节点,所以不会发生复杂的树的变形
所有 B+树都从高度为1的树开始慢慢增加高度
B+ 树在删除根节点的时候,由于存在冗余的节点,所以不会发生复杂的树的变形
InnoDB 里的 B+ 树中的每个节点都是一个数据页,非叶子节点的大小受页限制
插入删除
记叶子节点最多存储数据为 m 条
B+树插入
- 若为空树,创建一个叶子结点,然后将记录插入其中,此时这个叶子结点也是根结点,插入操作结束
- 针对叶子类型结点
- 根据 key 值找到叶子结点,向这个叶子结点插入记录
- 插入后,若当前结点 key 的个数小于等于 m-1,则插入结束
- 否则将这个叶子结点分裂成左右两个叶子结点,左叶子结点包含前 m/2 个记录,右结点包含剩下的记录,将第 m/2+1 个记录的 key 进位到父结点(索引类型结点)中,进位到父结点的 key 左孩子指针向左结点,右孩子指针向右结点。将当前结点的指针指向父结点
- 针对索引类型结点
- 若当前结点 key 的个数小于等于 m-1,则插入结束
- 否则,将这个索引类型结点分裂成两个索引结点,左索引结点包含前(m-1)/2 个 key,右结点包含 m-(m-1)/2 个 key,将第 m/2 个 key 进位到父结点中,进位到父结点的 key 左孩子指向左结点, 进位到父结点的 key 右孩子指向右结点,将当前结点的指针指向父结点,继续对父节点进行循环
B+树删除
- 删除叶子结点中对应的 key,删除后若结点的 key 的个数大于等于
Math.ceil(m-1)/2 – 1,删除操作结束,否则继续 - 若兄弟结点 key 有富余(大于
Math.ceil(m-1)/2 – 1),向兄弟结点借一个记录,同时用借到的 key 替换当前结点和兄弟结点共同的父结点中的 key,删除结束 - 若兄弟结点中没有富余的 key,则当前结点和兄弟结点合并成一个新的叶子结点,并删除父结点中的一个对应 key,将当前结点指向父结点(索引结点)
- 若索引结点的 key 的个数大于等于
Math.ceil(m-1)/2 – 1,则删除操作结束- 若兄弟结点有富余,父结点 key 下移,兄弟结点 key 上移,删除结束
- 否则当前结点,兄弟结点及父结点下移 key 合并成一个新的结点
- 将当前结点指向父结点,继续对父节点进行循环
注意,通过 B+树的删除操作后,索引结点中存在的 key,不一定在叶子结点中存在对应的记录
比较其他树
- 二叉查找树:极端情况下查找数据的时间复杂度为 O(n)
- 自平衡二叉树:树的高度较高,需要多次磁盘 IO,每次插入新节点的复杂度不定
- 红黑树:保证每次插入最多只需要三次旋转就能达到平衡,树的高度较高
- B 树:在数据查询中比平衡二叉树效率要高,但读取过程中非叶子节点中的数据也被加载进缓存,非叶子节点内可存储索引少
二级索引
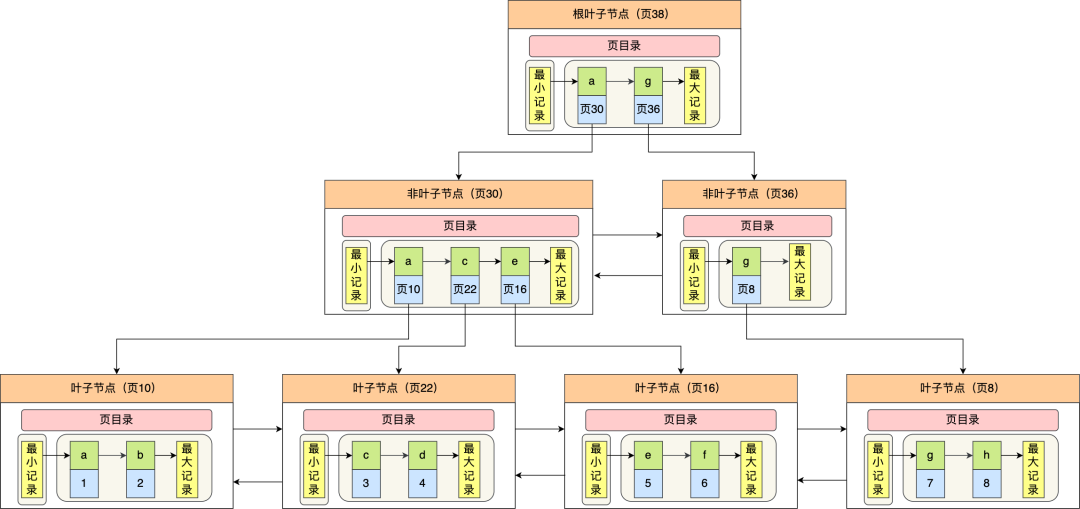
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据,且二级索引 B+树中记录按该索引值排序存放
二级索引中的 NULL 值在排序中默认最小,位于 B+树的最左边
回表&覆盖索引
回表指先通过二级索引在二级索引 B+树中找到主键,再通过主键在主键 B+树中找到相应记录,进而获取字段值
覆盖索引指仅通过二级索引的B+树就能够找到数据
可以通过将需要经常查询的字段设为二级索引,减少回表的次数,优化查询性能
前缀索引
主键索引:建立在主键字段上的索引,一张表最多一个
唯一索引:建立在UNIQUE字段上的索引,一张表可以有多个,允许包含空值
普通索引:建立在普通字段上的索引
前缀索引:对字符类型字段前n个字符建立的索引,可建立在类型为char、varchar、binary、varbinary的字段上
CREATE TABLE table_name (
id BIGINT AUTO_INCREMENT,
card_id CHAR(18) NOT NULL,
name VARCHAR(128) NOT NULL,
sex CHAR(6) NOT NULL,
registerDate DATETIME NOT NULL,
...
PRIMARY KEY(id) USING BTREE -- 主键索引
UNIQUE KEY(card_id,name) -- 唯一索引
INDEX(sex, registerDate) -- 普通索引
INDEX(name(5)) -- 前缀索引
);
联合索引
单列索引建立在单个字段上
联合索引建立在多个字段上
CREATE INDEX index_a_b_c ON product(a, b, c); -- 联合索引
联合索引的非叶子节点用多个字段的值作为 B+树的 key 值
联合索引当遇到范围查询 (>、<) 就会停止匹配:
SELECT * FROM t_table WHERE a > 1 AND b = 2- 无法使用联合索引
SELECT * FROM t_table WHERE a >= 1 AND b = 2- 对于
a=1, b=2使用了联合索引
- 对于
SELECT * FROM t_table WHERE a BETWEEN 2 AND 8 AND b = 2- 在 Mysql 中 BETWEEN 包含边界值,对于
a=2, b=2使用联合索引
- 在 Mysql 中 BETWEEN 包含边界值,对于
SELECT * FROM t_user WHERE a like 'j%' and b = 22- 对于首个符合通配符的 a 使用联合索引,之后顺序扫描返回行记录
最左匹配原则
使用联合索引时存在最左匹配原则,对于联合索引(a, b, c),如果查询时未使用最左端字段 a 则无法匹配上该联合索引
原理:联合索引的 B+树中按照索引从左到右的顺序进行排序,因此 a 全局有序,b、c 全局无序,局部相对有序
最左匹配原则会一直向右匹配,遇到范围查询则停止
实际开发工作中建立联合索引时,把索引区分度大的字段排在左边,使其能被更多的 SQL 使用到
索引区分度 = 某个字段中不同值的个数/表的总行数
索引下推
索引下推是 V5.6创建的查询优化策略
在通过联合索引进行查询,遍历二级索引 B+树过程中,找到匹配最左索引的二级索引记录后
- 使用索引下推
首先判断该记录中其他字段的值是否符合查询条件,直接过滤掉不满足条件的记录,减少回表次数 - 不使用索引下推
返回二级索引记录中主键值,执行器回表查询主键 B+树,取得记录后判断是否符合查询条件
只有当查询条件中包含了非主键索引中的所有列时,才能使用索引下推技术
索引失效
索引失效情况:
- 当使用左模糊匹配
like %xx或左右模糊匹配like %xx%时 - 在 WHERE 中对索引进行了计算,函数,类型转换等操作
- 从 MySQL 8.0 开始,索引特性增加了函数索引,可以针对函数计算后的值建立一个索引
- 在 WHERE 中 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列
- 联合索引中未遵循最左匹配原则
索引优化
覆盖索引优化
可通过建立联合索引的方式进行覆盖索引,避免回表
前缀索引优化
使用前缀索引以减小索引字段大小,进而增加单个索引页中存储的索引值,提高索引查询速度
局限性:
- ORDER BY无法使用前缀索引
- 无法把前缀索引用作覆盖索引
自增主键
自增主键可以使每次插入的新数据按顺序添加到已有数据后
非自增主键插入新数据需要移动现有数据,甚至需要从一个页面复制数据到另外一个页面,也即页分裂
索引设为 NOT NULL
查询选择索引
优化器计算每条SQL语句的成本,基于成本选择索引,优先使用成本最低的索引
一条 SQL 的成本 = CPU 开销 + IO 开销
MySQL 使用 like “%x“,索引一定会失效吗? | 小林coding (xiaolincoding.com)
可以通过 EXPLAIN 语句查看查询结果
Count
count(*) 和 count(1) 有什么区别?哪个性能最好? | 小林coding (xiaolincoding.com)
COUNT({parameter}) 统计符合查询条件的行记录中,{parameter} 不为 NULL 的行记录的个数
COUNT(1)统计表中的记录数
COUNT(*) 执行时 Mysql 将 * 参数转化为0处理
按性能排序:COUNT(*) = COUNT(1) > COUNT(主键字段) > COUNT(字段)
COUNT(1)、 COUNT(*)、 COUNT(主键字段)在执行的时候,如果表里存在二级索引,优化器就会选择二级索引进行扫描
如果要执行 COUNT(1)、 COUNT(*)、 COUNT(主键字段) 时,尽量在数据表上建立二级索引,优化器会自动采用 key_len 最小的二级索引进行扫描,相比于扫描主键索引效率高
COUNT(字段)会采用全表扫描的方式来统计,效率极差,需要统计时应将字段设为二级索引
InnoDB 存储引擎支持事务并发,所以无法像 MyISAM 一样,维护一个 row_count 变量以 O(1)时间复杂度取得 count 值