Mysql 语句执行过程
Mysql 语句执行过程
Mysql内部架构
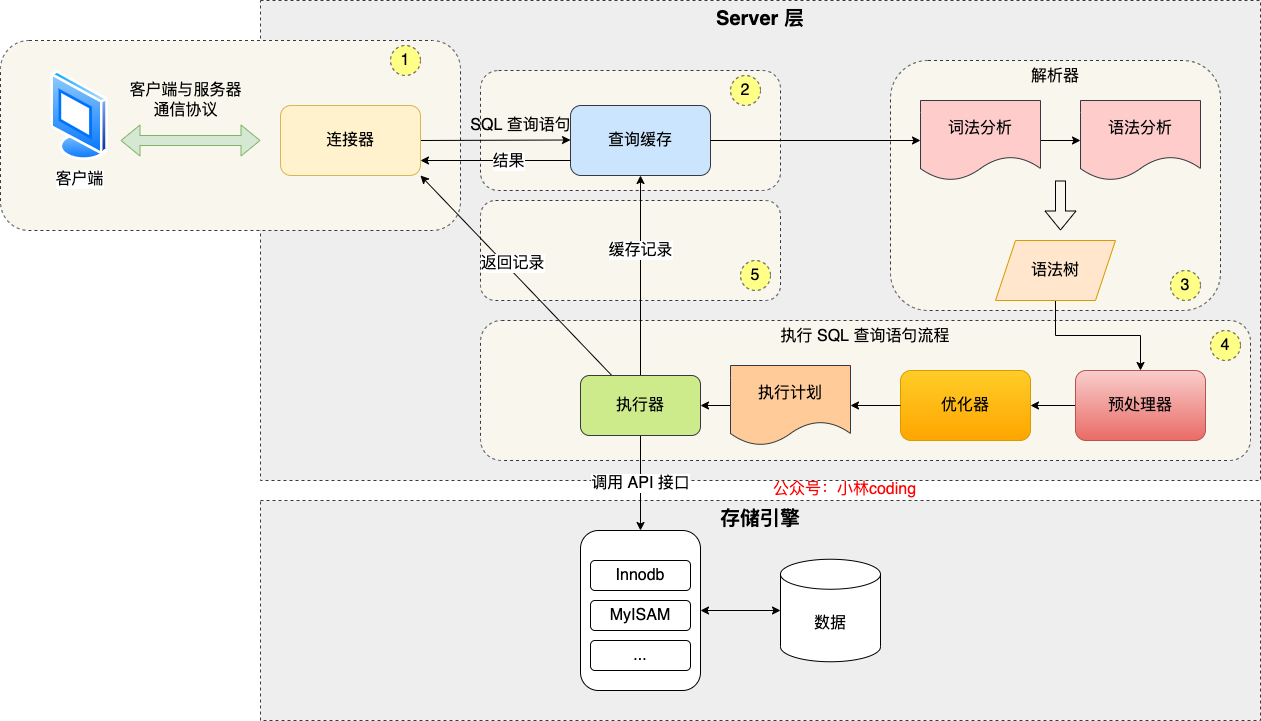
Mysql 的架构分为Server 层和存储引擎层
Server 层
Server 层负责建立连接、分析和执行 SQL
包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能
所有的内置函数(如日期、时间、数学和加密函数等)以及所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等
存储引擎层
存储引擎层负责数据的存储和提取
允许用户根据性能、特性和其他需求来选择不同的数据存储方式
- InnoDB:Mysql 默认和最通用的存储引擎,是一个事务安全(ACID 兼容)的 MySQL 存储引擎,并且还提供了行级锁和外键的约束
- MyISAM:不支持事务,但是查询速度快,适合于查询比较频繁,插入、修改比较少的场景
- MEMORY(HEAP):将表中的数据存储在内存中,查询速度快,但是不支持事务,适合于临时表的存储
- BDB(BerkeleyDB):支持事务,但是查询速度较慢,适合于高并发的场景
- ARCHIVE:只支持插入和查询,不支持修改和删除,适合于数据归档
Mysql 中可为同一数据库中的不同表格设定特定的存储引擎
连接器
mysql -h$ip -u$user -p
Mysql 基于 TCP 进行传输,连接需要经过 TCP 三次握手,断开连接经过 TCP 四次挥手
连接器在建立 TCP 连接后进行身份验证,通过则获取用户权限并保存,开始执行指令
Mysql 中空闲连接的最大空闲时长由 wait_timeout 参数控制,默认值是 8 h(28880s),如果空闲连接超过了这个时间,连接器自动将其断开
Mysql 服务支持的最大连接数由max_connections参数控制,V8.0.32默认为151
Mysql连接根据是否执行单个sql指令分为短连接和长连接
长连接可减少连接和断连的开销,但可能导致占用内存增加,过大内存会导致系统强行杀死进程,可定期断开长连接或者客户端通过mysql_reset_connection()主动将连接恢复至刚创建的状态
查询缓存(已废弃)
V8.0前Mysql在收到select语句后首先在Sever层的查询缓存中查找缓存的历史命令和执行结果,有则直接返回value,无则向下执行,获得结果后缓存
一个表的查询缓存会在表更新时清空,易导致缓存浪费,V8.0将查询缓存功能删除,V8.0以前可将参数 query_cache_type 设置成 DEMAND 关闭查询缓存
查询缓存&BufferPool:
查询缓存是 MySQL 的一种缓存机制,用于缓存查询结果,以便下次查询相同的数据时可以直接从缓存中获取,而不必再次执行查询
Buffer Pool是MySQL用于缓存磁盘上的数据页的内存区域,它可以减少磁盘I/O操作,提高查询效率
解析器
解析器在执行前对 SQL 语句进行词法分析和语法分析
词法分析识别SQL语句中的关键字并构建SQL语法树
语法分析根据语法规则判断SQL语句的正确性
执行
一条 SQL 语句的执行过程主要可以分为三个阶段:
- prepare 预处理阶段
- optimize 优化阶段
- execute 执行阶段
预处理器
预处理器负责检查 SQL 查询语句中的表或者字段是否存在
将 select *中的 *符号,扩展为表上的所有列
优化器
优化器负责确定 SQL 语句的执行方案
优化器根据查询成本进行索引选择
EXPLAIN
通过在查询语句前加入 EXPLAIN 可输出语句的执行计划
结果参数包括:
| 列名 | 描述 |
|---|---|
| id | 在一个大的查询语句中每个 SELECT 关键字都对应一个唯一的 id |
| select_type | SELECT 关键字对应的那个查询的类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上使用的索引 |
| key_len | 实际使用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| Extra | 一些额外的信息 |
EXPLAIN 语句输出的每条记录都对应着某个单表的访问方法,该条记录的 table 列代表着该表的表名
其中重点结果参数:
type 代表执行查询时的数据扫描类型(类型顺序从性能最好到最差排列)
system- 表中只有一条数据,是 const 类型的一个特例const- 根据主键或者唯一二级索引列与常数进行等值匹配,结果只有一条eq_ref- 唯一索引扫描,通常用于多表联合的查询中,其中使用主键或唯一索引作为查询的关联条件ref- 非唯一索引扫描,使用普通的二级索引或者索引的前缀来执行查找,或者联接不能基于关键字选择单个行的时候range- 索引范围扫描,只检索给定范围的行记录index- 全索引扫描,仅遍历索引树ALL- 全表扫描
possible_keys 代表可能的索引选择,可能使用的索引越多,查询优化器计算查询成本时就得花费更长时间,在查询中可使用 FORCE INDEX、USE INDEX 或者 IGNORE INDEX 强制使用或忽视 possible_keys 列中的索引
key 则代表实际选择的索引,在普通字段名外包含两种特殊值:
PRIMARY- 进行了主键索引NULL- 进行了全表扫描
key_len 表示当优化器决定使用某个索引执行查询时,该索引记录的最大长度,如果该索引列可以存储 NULL 值,则 key_len 比不可存储时多1个字节
rows 为解析器预估的扫描数据行数,通常小于实际值
Extra 参数包含多种情况
Using filesort:当查询语句中包含排序 order by 操作且无法利用索引直接完成排序操作时,不得不选择相应的排序算法甚至通过文件排序,效率低Using temporary:使用了临时表保存中间结果,MySQL 在对查询结果排序时使用临时表,常见于排序 order by 和分组查询 group by,效率低Using index:使用了覆盖索引,避免了回表操作,效率高Using where:存储引擎搜到记录后根据 WHERE 条件进行了进一步过滤Using join buffer:在获取连接条件时没有用到索引,并且需要连接缓冲区来存储中间结果Using index condition: 使用了索引下推Impossible where: 查询语句的 WHERE 子句永远为 FALSENo tables used:查询语句没有 FROM 子句
在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度, MySQL 一般为其分配一块名为
join buffer的内存块来加快查询速度
执行器
查询
- 执行器根据是否使用索引调用存储引擎的不同接口进行查询
- 调用索引 - 引擎通过 B+树定位记录,返回相应记录或未找到错误
- 全表扫描 - 引擎从第一条记录开始依次返回记录,读完所有记录后返回读取完毕信息
- 执行器每次获取记录后判断是否符合查询条件,符合则立刻返回该记录给客户端
- 客户端等待查询语句完成后显示全部结果
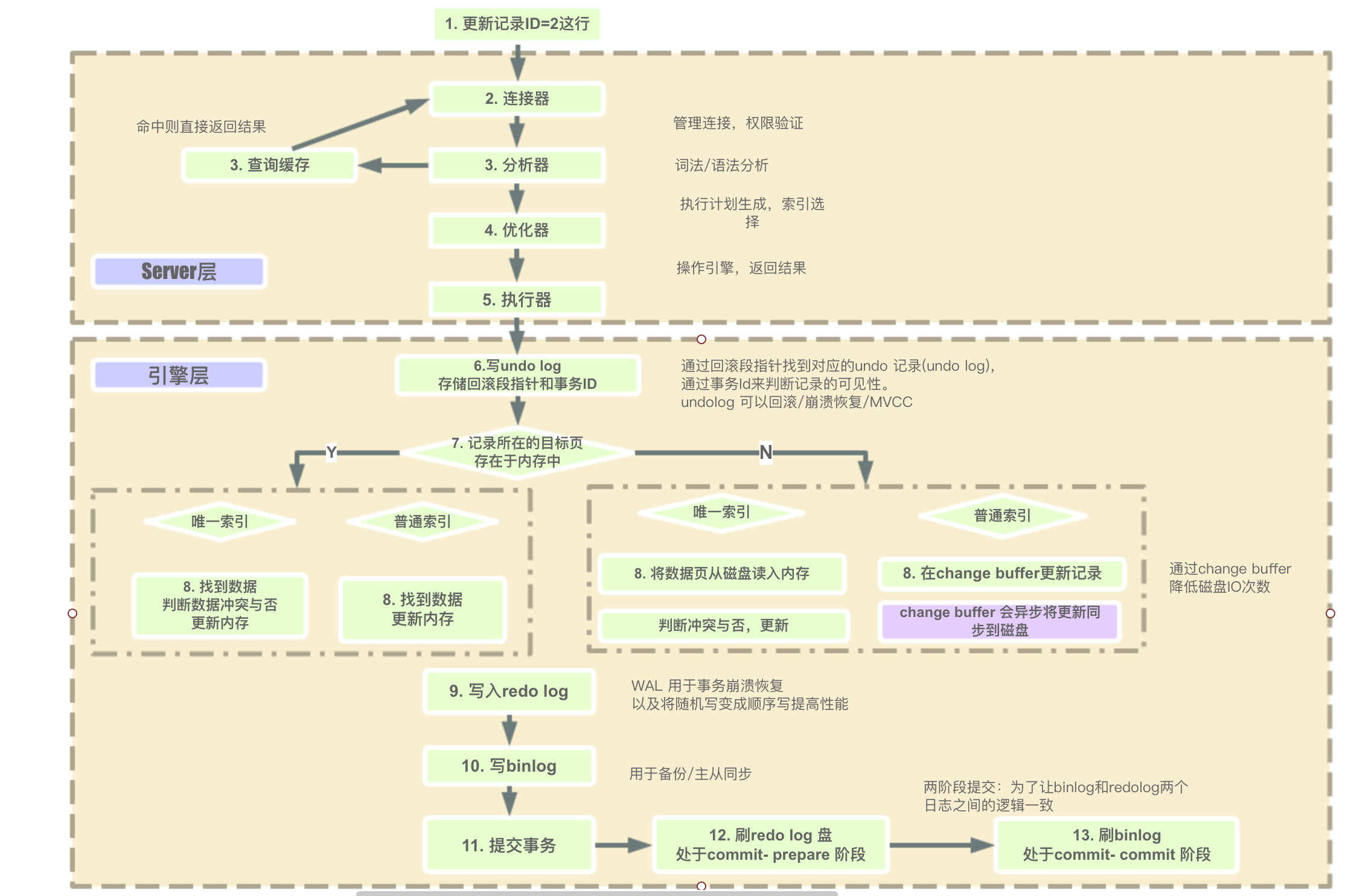
更新
- 开启事务,更新记录前记录 undo log,undo log 会写入 Buffer Pool 中的 Undo 页面
- 查询记录所在数据页
- 在 Buffer pool 中,直接将池中记录返回执行器
- 不在内存中
- 更新字段为唯一索引,将记录所在数据页读入 Buffer Pool,返回给执行器
- 更新字段不为唯一索引,InnoDB 将更新操作缓存在 change buffer 中
- InnoDB 更新 Buffer pool 中记录,将相应数据页标为脏页,记录 redo log
- 后续由后台线程选择合适时机将脏页写入磁盘
- 执行完成后记录该语句对应的 binlog
- 执行器调用引擎的提交事务接口
- 事务的两阶段提交:commit 的 prepare 阶段:引擎把刚刚写入的 redo log 刷盘
- 事务的两阶段提交:commit的commit阶段:引擎binlog刷盘